An Automated Evaluation Framework for Unit Test-Driven LLM Code Generation
Introduction: Problem & Motivation
Growing Software Complexity
Traditional development methods struggle to keep pace with increasing system complexity
LLMs as Code Generators
Promising solution for efficient code generation, but reliability and comprehension require thorough evaluation
Test-Driven Approaches
Providing test cases as input to guide LLMs toward producing more accurate and reliable code
Empirically analyze effectiveness across multiple dimensions
Introduction: Test-Driven Prompting
Normal Prompting
###Prompt
Check if numbers are closer
than threshold.
>>> has_close_elements(
[1.0, 2.0, 3.0], 0.5)
False
###Signature
def has_close_elements(
numbers: List[float],
threshold: float) -> bool:Test-Driven Prompting (TDP)
###Prompt + Signature
(same as baseline)
###Test (50% of suite)
assert candidate(
[1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.) == True
assert candidate(
[1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.5) == False
assert candidate(
[1.0, 2.0, 5.9, 4.0, 5.0], 0.5) == TrueKey Difference: TDP adds explicit test cases as executable specifications (50% public tests, 50% withheld for validation)
Introduction: Why Test-Driven Prompting?
| Strategy | Mechanism | Improves | Auto-Evaluation? |
|---|---|---|---|
| Chain-of-Thought (CoT) | Step-by-step reasoning decomposition | How the model reasons | ✗ No |
| Structured CoT | CoT + programming constructs | How (up to 13.79% Pass@1) | ✗ No |
| Persona Prompting | Role assignment to shape perspective | Code quality, not correctness | ✗ No |
| Few-Shot | Concrete input-output examples | What to produce | ✗ No |
| TDP | Executable test assertions | What + correctness criteria | ✓ Built-in |
TDP is orthogonal to reasoning-enhancement techniques (CoT) and role-setting (Persona) — suggesting potential complementarity.
Literature Review: Selected Prior Works Test-Driven LLM Code Generation
Related Research Comparison
| Reference | Year | Dataset | LLM Models | Contribution | Limitation |
|---|---|---|---|---|---|
| Liu et al. | 2025 | HumanEval variants | 9 models (GPT-4, Mixtral, Llama3, etc.) | Autonomous self-debugging framework with test dependency graphs; 10.41% average improvement | All benchmarks HumanEval-based; No systematic model size comparison; Pass@k attempts undisclosed |
| Mathews & Nagappan | 2024 | HumanEval, MBPP, CodeChef | GPT-4, Llama 3 | 9-30% accuracy improvement with remediation loops | TDP applied only to failed cases; Non-standard difficulty analysis; Limited model scope |
| Fakhoury et al. | 2024 | HumanEval, MBPP | GPT 3/3.5 variants | Semi-automated TiCODER workflow; 38% improvement | Requires human intervention; TDP not isolated; No difficulty analysis |
| Piya & Sullivan | 2024 | Custom Leetcode | GPT-3.5 | 5:8 efficiency ratio; TDP best practices | Single model; Lacks statistical rigor; TDP not isolated; Low test coverage |
| Chen et al. | 2022 | HumanEval, MBPP, APPS, Contests | Codex, INCODER, CODEGEN variants | Dual execution agreement; 18.8% improvement | Outdated models; No difficulty analysis; TDP not isolated |
| Lahiri et al. | 2022 | HumanEval, MBPP | code-davinci-002 | Interactive test-driven specification | Requires user feedback; Single model; TDP not isolated; No difficulty analysis |
Literature Review: The Research Gap
Test-Driven Prompting (TDP) shows promise but has critical limitations:
- Evaluation bias: TDP applied only to failed cases (selection bias)
- Limited scope: Single language focus (Python bias)
- Narrow model coverage: 1-2 models, missing open-source alternatives
- Lack of explainability: Works, but when and why?
Research Questions & Objective: Primary Focus
What is the performance of test-driven code generation across programming languages of different popularity and type nature?
Scope: Python, JavaScript, C++, TypeScript, PHP, Ruby, Go, C#
Objective: Measure TDP performance across 8 languages to address language bias in existing research
What is the performance of test-driven code generation on various models with differing characteristics?
Scope: Closed/open-source, varying sizes, general vs specialized
Objective: Compare TDP effectiveness across closed/open-source models, varying sizes, and specialized vs general-purpose LLMs
Research Questions & Objective: Additional Dimensions
What is the relationship between programming problem difficulty and LLM performance?
Objective: Analyze LLM performance across problem difficulty levels from introductory to competition-level
What is the relationship between test suite completeness and LLM performance?
Objective: Quantify the relationship between test suite completeness and LLM performance
How can a decision framework guide developers in selecting appropriate LLMs for platform-specific development?
Objective: Develop decision framework for LLM selection in mobile development (Android/Java, iOS/Swift) based on accuracy, budget, and deployment needs
Methodology: Experimental Framework
Four-Stage Pipeline
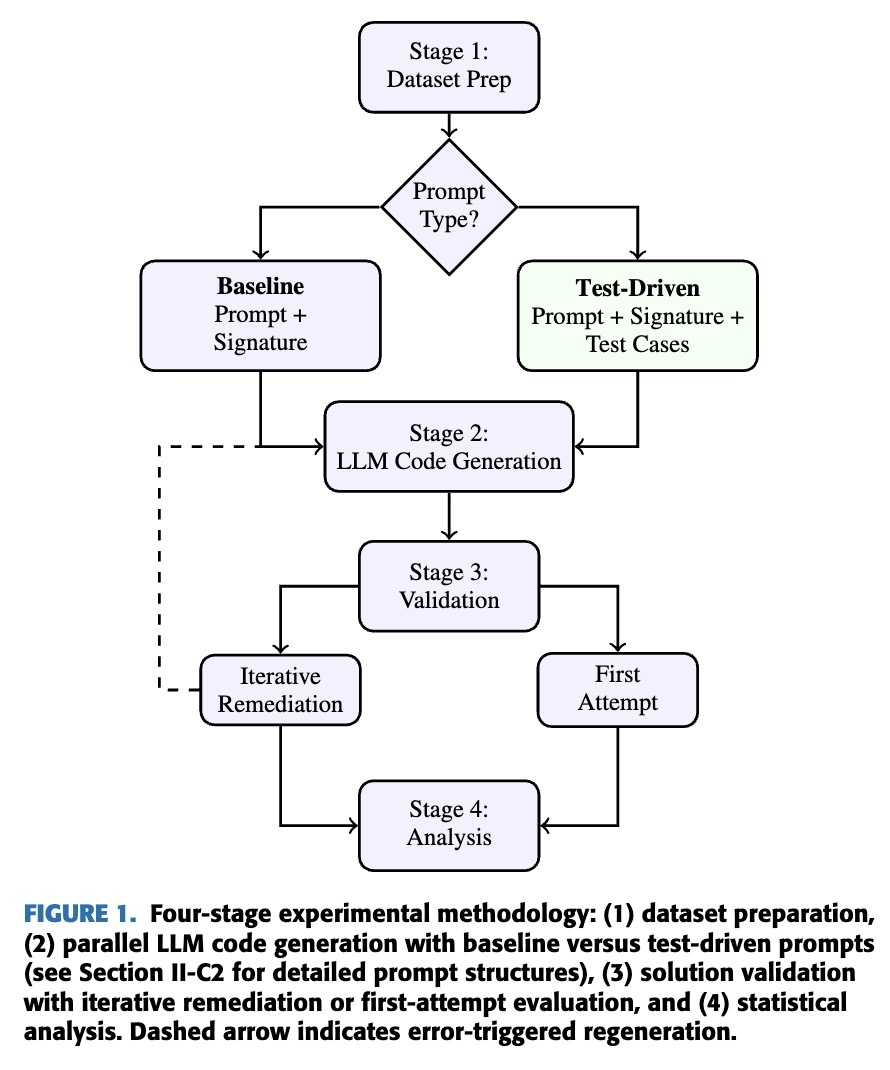
- Stage 1 - Dataset Prep: Prepare two prompt variants for each problem: (1) baseline prompt with problem description and function signature, (2) test-driven prompt with additional explicit test cases
- Stage 2 - LLM Code Generation: Process both prompt variants in parallel through selected LLMs to generate code solutions
- Stage 3 - Validation: Automated test execution in controlled setting with two configurations: direct evaluation (first attempt) and iterative remediation (error feedback loops)
- Stage 4 - Analysis: Comprehensive statistical analysis to assess model performance and test-driven prompting efficacy
Methodology: Large Language Models Selection
8 Models Across 3 Dimensions
| Model | Source Type | Size | Specialization |
|---|---|---|---|
| GPT-4o | Closed Source | Large | General Purpose |
| GPT-4o-mini | Closed Source | Small | General Purpose |
| Claude 3.5 Sonnet | Closed Source | Large | General Purpose |
| Claude 3.5 Haiku | Closed Source | Small | General Purpose |
| Qwen 2.5 Coder 32B | Open Source | 33B | Coding Specialized |
| Qwen 2.5 Coder 14B | Open Source | 14B | Coding Specialized |
| Qwen 2.5 Coder 7B | Open Source | 7B | Coding Specialized |
| Qwen 2.5 Coder 3B | Open Source | 3B | Coding Specialized |
Strategic Dimensions
- Source Type: Closed-source vs open-source dichotomy examines if proprietary models' performance justifies costs
- Model Size: Different sizes within families enable analysis of how computational scale impacts effectiveness
- Specialization: General-purpose vs coding-specialized models investigates domain-specific training advantages
Comprehensive Coverage: 4 closed-source + 4 open-source models spanning 3B-Large parameters
Methodology: Programming Languages Selection
2×2 Factorial Design
| Language | Frequency | Type System |
|---|---|---|
| Python | High | Dynamic |
| JavaScript | High | Dynamic |
| C++ | High | Static |
| TypeScript | High | Static |
| PHP | Medium | Dynamic |
| Ruby | Medium | Dynamic |
| Go | Medium | Static |
| C# | Medium | Static |
Design Rationale
- High & Medium Frequency: Classifications based on weighted formula combining GitHub usage and TIOBE index (Cassano et al., 2023)
- Dynamic: Runtime type checking
- Static: Compile-time type checking
Balanced Design: 4 languages per cell enables robust statistical analysis
Cassano, F., et al. (2023). MultiPL-E: A Scalable and Polyglot Approach to Benchmarking Neural Code Generation. IEEE TSE, 49(7).
Methodology: Experimental Resources
Datasets & Evaluation Metrics
4 Benchmark Datasets
- HumanEval: 164 function-level problems
- MBPP: 399 function-level problems
- MultiPL-E: 8 programming languages
- Code Contests: 404 competition-level problems (EASY/MEDIUM/HARD)
2 Key Metrics
- First-attempt accuracy: Initial code generation success
- Remediation accuracy: Success after up to 5 iterations
Methodology: Experimental Resources
Technical Implementation Details
LLM Configuration & Hyperparameters
- Temperature: 0.0 (deterministic generation)
- Seed: 1000 (reproducible results)
- Max Tokens: Default model limits (GPT-4o: 4096, Claude 3.5: 8192)
- Remediation attempts: Maximum 5 iterations
LLM Access
- OpenRouter API: GPT models (gpt-4o-2024-11-20, gpt-4o-mini-2024-07-18), Claude models (claude-3.5-sonnet, claude-3.5-haiku)
- HuggingFace Endpoints: Qwen models (Qwen2.5-Coder-32B/14B/7B/3B-Instruct)
- Evaluation Environment: Python 3.11.13 with numpy, pandas, scipy, pingouin
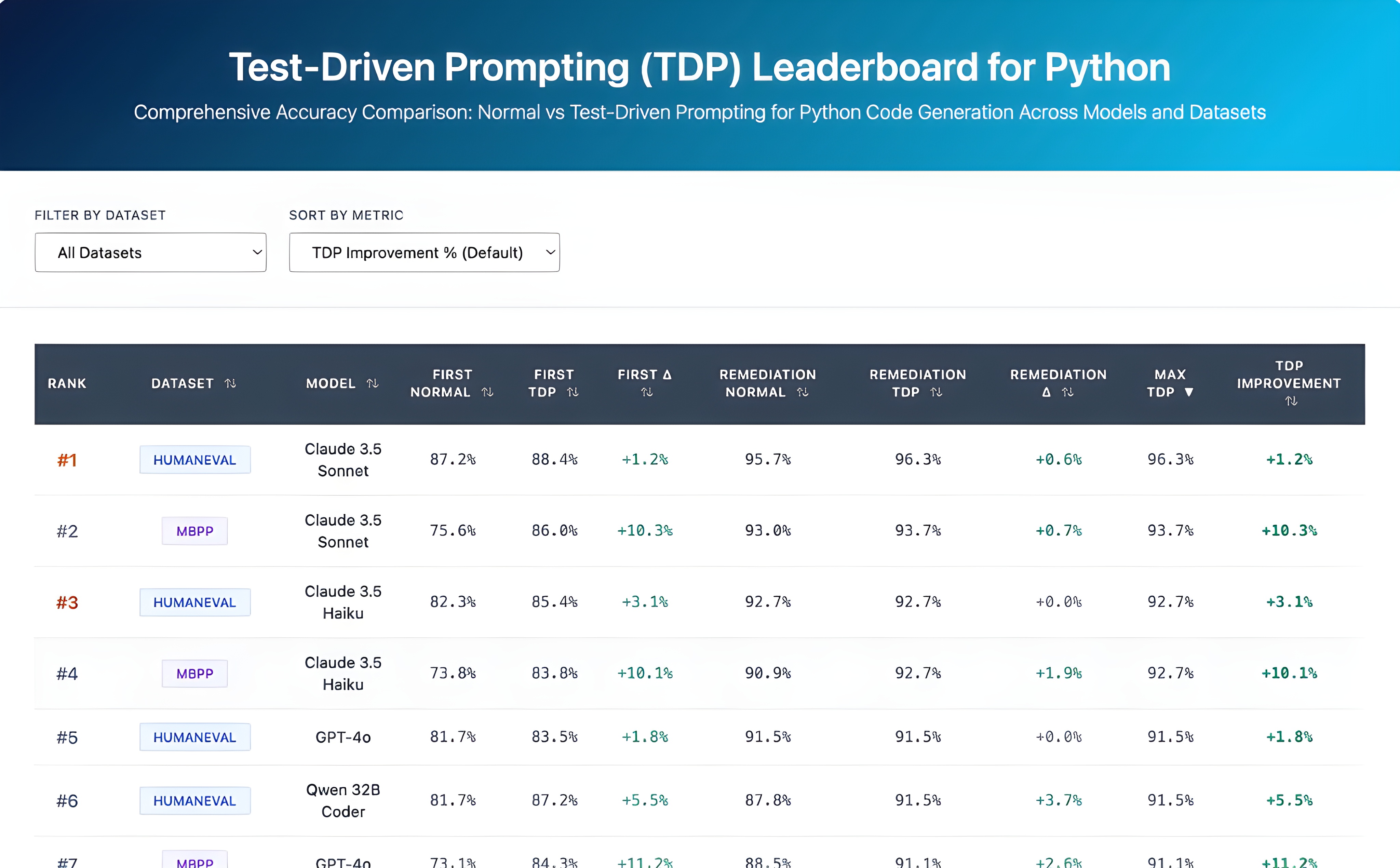
Results: RQ1 - Performance Across Mainstream Programming Languages
Overall Effectiveness of Test-Driven Prompting
Summary Statistics (32 comparisons)
- Success rate: 75% (24/32 improved)
- Average improvement: +4.63 pp
- 95% CI: [2.93, 6.33]
- Statistical significance: p < 0.001
- Cohen's d: 0.87 (large effect)
Distribution Characteristics
- Range: -3.12 to +14.14 pp
- Median: 4.88 pp
- IQR: 0.47 to 8.46 pp
- SD: 4.71
- Regressions: Only 5/32 (15.6%), all modest (< 3.5 pp)
Results: RQ1 - 2×2 Design - Frequency × Type System Analysis
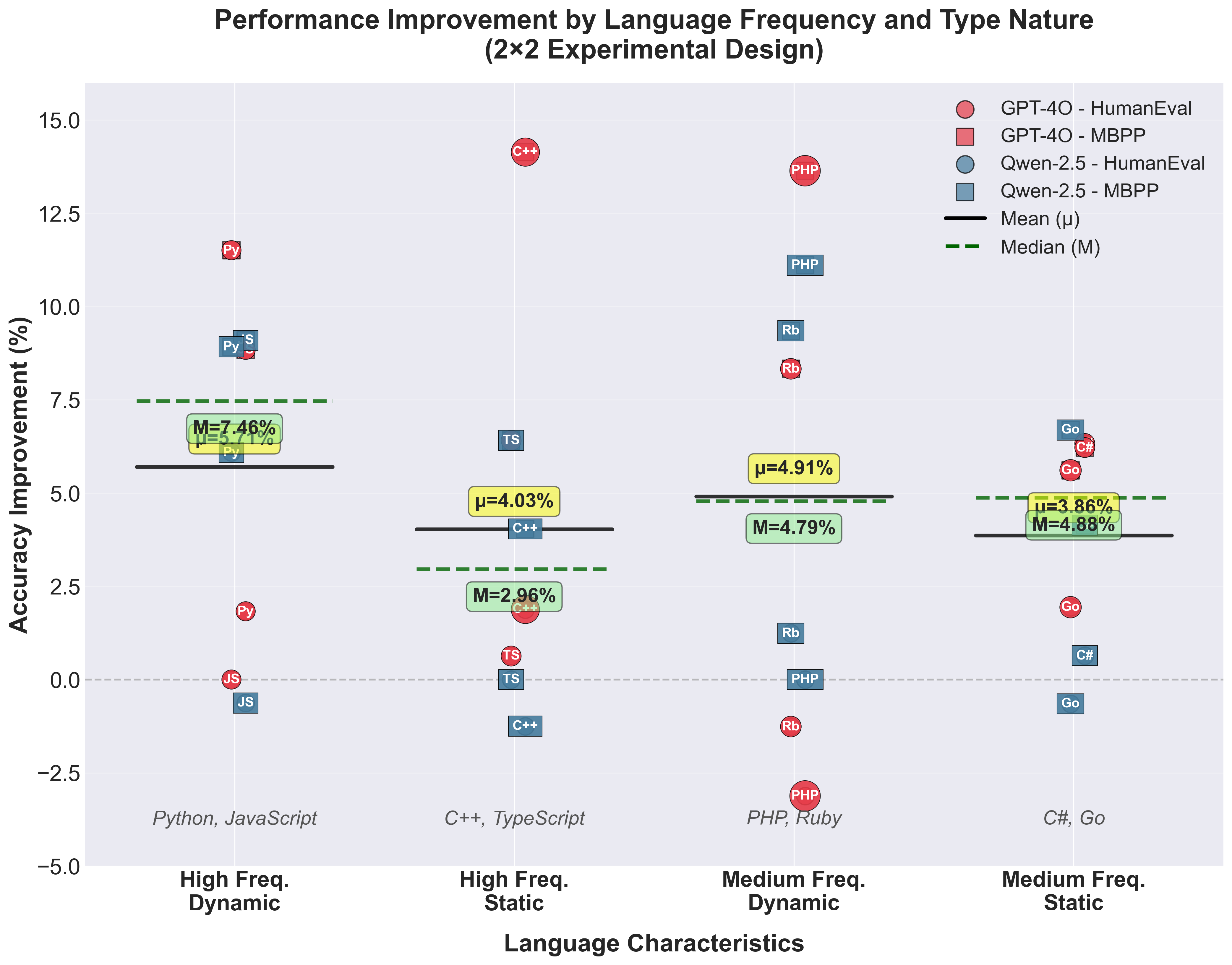
Group Statistics
| Category | Mean | Median |
|---|---|---|
| High-Freq Dynamic | 5.71% | 7.46% |
| High-Freq Static | 4.03% | 2.96% |
| Med-Freq Dynamic | 4.91% | 4.79% |
| Med-Freq Static | 3.86% | 4.88% |
Note: Black lines = group means (μ), green dashed lines = medians (M)
Within-Group Variation
- Range: 7-15 percentage points
- Far exceeds between-category differences (1-2 pp)
Example: Python (+7.09 pp) vs JavaScript (+4.32 pp)
Both dynamic high-frequency, yet 3 pp difference!
Results: RQ2 - Universal Effectiveness Across Model Architectures
Perfect Success Rate Across All 8 Models
Overall Statistics
- Success rate: 16/16 (100%)
- Average improvement: +6.09%
- 95% CI: [4.01, 8.18]
- P-value: < 0.001
- Cohen's d: 1.08 (large)
- Shapiro-Wilk: 0.89 (p = 0.05)
Model-Specific Improvements
| Model | First | Remed |
|---|---|---|
| GPT-4o | +6.54% | +1.29% |
| GPT-4o-mini | +5.36% | +1.29% |
| Claude Sonnet | +5.76% | +0.66% |
| Claude Haiku | +6.56% | +0.93% |
| Qwen 32B | +7.08% | +3.47% |
| Qwen 14B | +7.43% | +7.74% |
| Qwen 7B | +6.58% | +6.70% |
| Qwen 3B | +3.45% | +3.68% |
THE strongest empirical finding: Perfect success rate + large effect size = model-agnostic effectiveness
Results: RQ2 - The Democratization Effect
Smaller Models + TDP Rival Larger Baselines
80% Success Rate (8/10): Small+TDP ≥ Large Baseline
GPT Family
GPT-4o-mini + TDP (80.7%)
vs GPT-4o baseline (77.4%)
+3.3 pp,
16.7× cheaper
HumanEval: Perfect parity
(81.7%)
MBPP: Mini wins 79.6% vs 73.1% (+6.5 pp)
Claude Family
Haiku + TDP (84.6%) vs
Sonnet baseline (81.4%)
+3.2 pp
advantage
Qwen Cascade
- 14B+TDP vs 32B: +4.3 pp (HE), +8.2 pp (MBPP)
- 7B+TDP vs 14B: Match (HE), +4.9 pp (MBPP)
- 3B+TDP vs 7B: -0.6 pp (HE), +2.9 pp (MBPP)
Economic transformation: Smaller models + TDP achieve competitive performance at fraction of cost
Results: RQ3 - The Inverse Difficulty Relationship
TDP Addresses Specification, Not Algorithmic Complexity
TDP Improvement by Difficulty
- EASY: +55.22 pp
- MEDIUM: +26.79 pp
- HARD: +12.96 pp
Inverse pattern: Larger improvements on easier problems!
The Paradox: Normal Prompting
- EASY: 0.0% (worst!)
- MEDIUM: 2.89%
- HARD: 11.11% (best!)
Remediation recovery on
EASY:
0.0% → 45.77% (+45.77 pp)
Specification errors recoverable!
Why 0%? 67-88% of Easy failures = trailing newlines. 100% of Easy require them vs 92.5% Med, 79.2% Hard—no "escape routes."
Mechanism: Easy problems = low algorithmic demands + low specification clarity. Hard problems = high algorithmic demands + higher specification clarity. TDP eliminates specification disadvantage.
Results: RQ4 - Test Suite Completeness Effects
Positive Relationship: Full Coverage Yields 2.4× Greater Improvement
Performance by Test Ratio
| Ratio | Avg Tests | Δ | Effect | P-value |
|---|---|---|---|---|
| 0.25 | 1.56 | +2.90 pp | d=1.24 | 0.005 |
| 0.5 | 3.34 | +3.35 pp | d=1.23 | 0.099 |
| 0.75 | 5.07 | +4.27 pp | d=1.97 | 0.018 |
| 1.0 | 7.20 | +6.85 pp | d=2.83 | 0.009 |
Ratio 0.5: Although p=0.099 slightly exceeds the conventional 0.05 threshold, the Wilcoxon signed-rank test statistic of 0.0 indicates perfect unidirectional effectiveness (all models improved, no regressions), demonstrating consistent practical effectiveness despite the limited sample size.
Model-Dependent Patterns
Qwen models: Plateau at 0.5-0.75 (5.49-6.09 pp), jump to 8.53-9.14 pp at 1.0
GPT models: U-shaped pattern with dip at 0.5 (0.61-1.22 pp), recover to ~4.9 pp at 1.0
Key insight: Even minimal coverage (1.56 tests) provides meaningful gains (+2.90 pp, p=0.005)
Practical recommendation: 50% test suite offers good cost-benefit trade-off
Results: RQ5 - Decision Framework for LLM Selection
Complete Decision Tree with All 8 Recommendations
| Node | Question | Answer | Next | Recommendation |
|---|---|---|---|---|
| 1 | First-Attempt Correct? | Yes | → 2a | First-attempt scenario |
| No | → 2b | Multi-attempt scenario | ||
| 2a | Budget? | High | → 3a | Higher budget |
| Low | → 3b | Lower budget | ||
| 2b | Budget? | High | → 3c | Higher budget |
| Low | → 3d | Lower budget | ||
| 3a | Self-Host? | Yes | ✓ | Qwen-32B First (And: 75.16%, iOS: 78.25%) |
| No | ✓ | GPT-4o First (And: 75.81%, iOS: 81.04%) | ||
| 3b | Self-Host? | Yes | ✓ | Qwen-14B First (And: 71.52%, iOS: 74.86%) |
| No | ✓ | GPT-4o-mini First (And: 68.37%, iOS: 73.71%) | ||
| 3c | Self-Host? | Yes | ✓ | Qwen-32B Multi (And: 78.56%, iOS: 85.97%, $5/hr) |
| No | ✓ | GPT-4o Multi (And: 80.36%, iOS: 88.87%) | ||
| 3d | Self-Host? | Yes | ✓ | Qwen-14B Multi (And: 73.49%, iOS: 78.07%, $1.8/hr) |
| No | ✓ | GPT-4o-mini Multi (And: 74.64%, iOS: 80.72%) |
Note: Multi-attempt adds 5-8 pp | iOS consistently 4-7 pp > Android | And = Android
Contributions & Conclusion: Practical Implications
1. Universal Effectiveness
- Model-agnostic: 16/16, d=1.08
- Cross-language: 75%, 32 comparisons
- Test-robust: p=0.005, d=1.23 at ratio 0.25
2. Specification-Driven
- MBPP +8.40 pp (100%) vs HumanEval +0.85 pp (50%)
- Normal EASY 0.0%→45.77% recovery proves specification focus
- TDP hierarchy: 55.22%→29.69%→24.07%
3. Democratization Effect
- 8/10 (80%) smaller+TDP ≥ larger baseline
- GPT-4o-mini+TDP > GPT-4o by +3.3 pp (16.7× cheaper)
- Qwen 32B (USD 0.21/M) matches Sonnet (USD 12.50/M) = 59× savings
4. Test Suite Design
- Specification-clarifying tests (edge cases, formats)
- Start minimal (1-2 tests provide significant value)
Contributions & Conclusion: Open Source Contribution
Reproducibility, Extensibility and Community Resources
Contributions & Conclusion: Limitations and Future Directions
Non-functional quality not evaluated
Evaluate complexity, efficiency
Class-level, codebase-level unexplored
Class-level, codebase-level generation
UI code, data pipelines unexplored
UI code, data pipelines, non-algorithmic
Only mobile (iOS/Android) examined
Desktop, OS, Frontend, Backend
Sequential selection only
Coverage-based, diversity-based selection
Publications
-
IEEE Access
Accepted for Publication
https://ieeeaccess.ieee.org/
Indexing: WoS Q2, Scopus Q1 | SJR: 0.849 | IF: 3.6
Publishing: RQ2 and RQ3 -
International Journal of Interactive Mobile Technologies (i-JIM)
Accepted for Publication
https://online-journals.org/index.php/i-jim
Indexing: Scopus Q3 | SJR: 0.413
Publishing: RQ5
Publications - Paper Screenshots

IEEE Access - Accepted

i-JIM - Accepted
Thank You for Your Attention
Questions & Discussion
I welcome your questions and feedback
Muhammad Adnan Rizqullah
Advisor: Dr. Emad Yosif Albassam
King Abdulaziz University
Faculty of Computing and Information Technology
Appendix
Methodology: Experimental Design
Core Methodological Principles
1. Fully Paired Evaluation
Every problem-model combination tested with BOTH baseline AND TDP
→ Eliminates selection bias
2. Consistent Prompting
Baseline: Problem + function signature
TDP: Baseline + 50% test cases
→ 50% withheld for validation
Methodology: Experimental Design
Remediation and Statistical Analysis
3. Comprehensive Remediation Loop
Up to 5 attempts with error feedback for BOTH strategies
→ Equal opportunities prevent compounded advantages
4. Rigorous Statistical Analysis
Shapiro-Wilk normality → Paired t-tests / Wilcoxon
Cohen's d effect sizes + 95% confidence intervals
→ Ensures practical significance
RQ1: 2×2 Design - Key Insights
Categorical Effects vs Within-Group Variation
Weak Categorical Effects
- High-frequency advantage: +0.5 pp
- Dynamic type advantage: +1.4 pp
BUT: Means vs medians inconsistent
Med-Freq Static: mean 3.86% vs median 4.88%
Within-Group Variation
- Range: 7-15 percentage points
- Far exceeds between-category differences (1-2 pp)
Example: Python (+7.09 pp) vs JavaScript (+4.32 pp)
Both dynamic high-frequency, yet 3 pp difference!
RQ1: Individual Language Characteristics Dominate
Python vs TypeScript: Contrasting Outcomes
Python's Exceptional Performance
+7.09 pp improvement
- More than 2× improvement vs TypeScript (+3.36 pp)
- Both are popular, well-supported languages
- Likely due to extensive representation in test-driven development contexts in training data
TypeScript's Modest Gains
+3.36 pp improvement (lowest)
- Despite being static high-frequency language
- Type system already provides substantial specification constraints
- Reduces marginal benefit of additional test case guidance
RQ1: Individual Language Characteristics Dominate
Within-Category Contradictions
Within-Category Contradictions
Same category, different performance:
- High-Freq Dynamic: Python (+7.09 pp) vs JavaScript (+4.32 pp) = 2.77 pp gap
- High-Freq Static: C++ (+4.70 pp) vs TypeScript (+3.36 pp) = 1.34 pp gap
- These within-category gaps exceed the categorical effects (+0.5 to +1.4 pp)
Key finding: TDP effectiveness depends on alignment between problem characteristics and language-specific training patterns, not on broad categorical distinctions
RQ1: Benchmark Type as Primary Differentiating Factor
10-Fold Difference Between MBPP and HumanEval
MBPP Results
- Average improvement: +8.40 pp
- Success rate: 100% (16/16)
- Range: +4.04 to +14.14 pp
- Top 5 improvements: All from MBPP
HumanEval Results
- Average improvement: +0.85 pp
- Success rate: 50% (8/16)
- Range: -3.12 to +6.33 pp
- All 5 regressions: From HumanEval
Critical Insight
10× difference between benchmarks vs 2× max within language types
Mechanism: Specification clarity matters more than language properties
Finding: Problem characteristics (test suite comprehensiveness, baseline difficulty) >>> intrinsic language properties
RQ1: Extreme Cases - Top Improvements and Regressions
Top 5 Improvements (All MBPP)
| Lang | Model | Δ |
|---|---|---|
| C++ | GPT-4O | +14.14 pp |
| PHP | GPT-4O | +13.64 pp |
| Python | GPT-4O | +11.51 pp |
| PHP | Qwen | +11.11 pp |
| Ruby | Qwen | +9.35 pp |
Top 5 Regressions (All HumanEval)
| Lang | Model | Δ |
|---|---|---|
| PHP | GPT-4O | -3.12 pp |
| Ruby | GPT-4O | -1.26 pp |
| C++ | Qwen | -1.25 pp |
| Go | Qwen | -0.65 pp |
| JS | Qwen | -0.63 pp |
Notable: PHP with GPT-4O shows largest improvement (+13.64 pp on MBPP) AND largest regression (-3.12 pp on HumanEval) - same language-model, different benchmark!
Results: RQ1 - Language-Specific Results
Individual Variation Exceeds Categorical Patterns
Average Improvement by Language
- Python: +7.09 pp (highest)
- PHP: +5.41 pp
- C++: +4.70 pp
- Ruby: +4.42 pp
- JavaScript: +4.32 pp
- C#: +4.30 pp
- Go: +3.40 pp
- TypeScript: +3.36 pp (lowest)
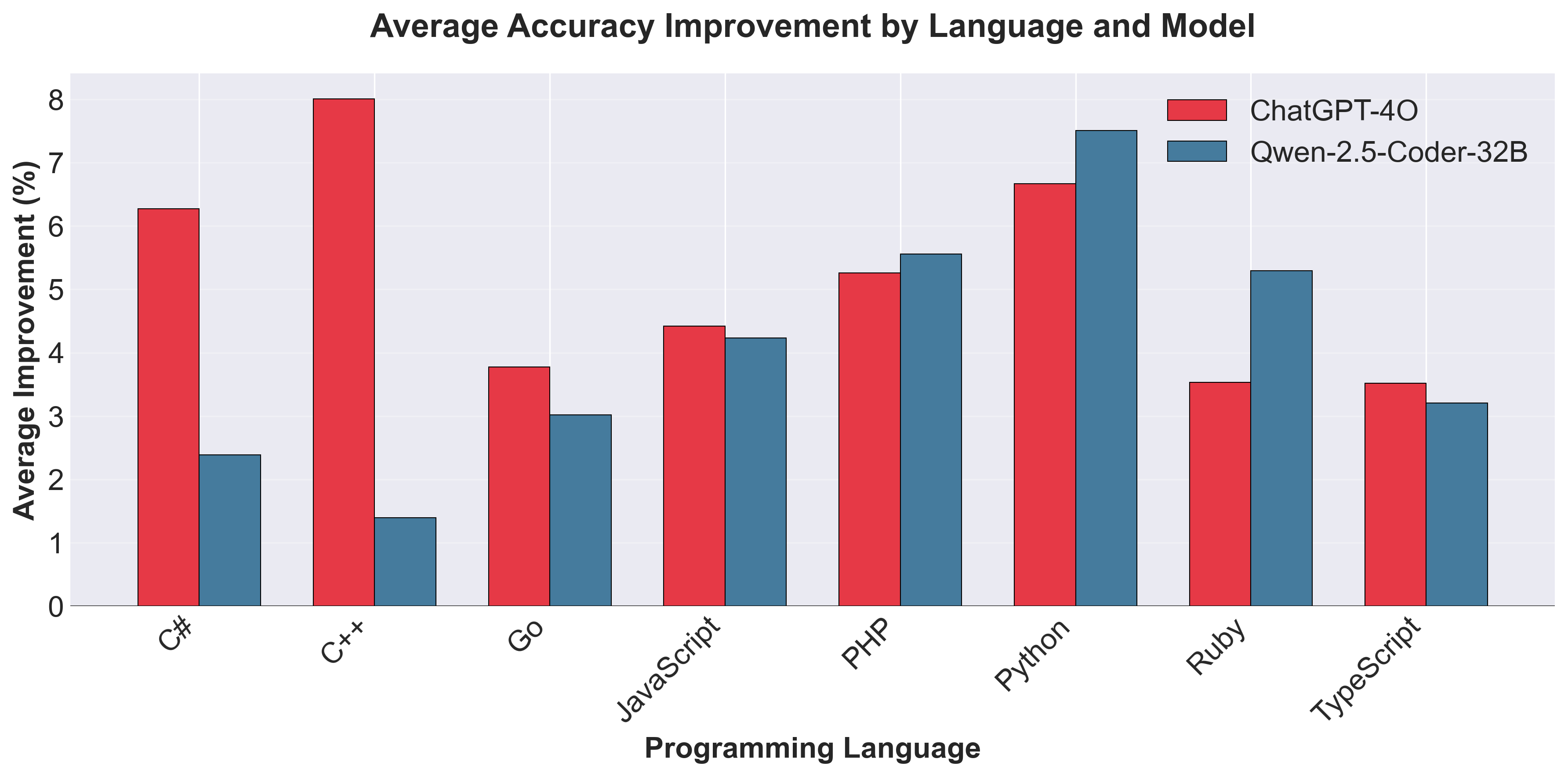
Key insight: Python shows 2× improvement compared to TypeScript/Go, despite all being popular languages
Results: RQ2 - Source Type Neutrality
Closed-Source vs Open-Source Performance Parity
TDP Effectiveness by Source
- Closed-source: +6.06% average
- Open-source: +6.14% average
- Difference: 0.08 pp (negligible)
Finding: TDP effectiveness independent of proprietary vs community-developed models
Performance Parity Example
Qwen 32B + TDP: 84.7%
GPT-4o + TDP:
83.9%
Open-source matches closed-source!
Cost Advantage:
Qwen 32B:
$0.21/M tokens
Claude Sonnet: $12.50/M tokens
59× cost savings!
Practical implication: Organizations with self-hosting capabilities can achieve competitive accuracy at dramatically lower cost
Results: RQ2 - First-Attempt Performance and Computational Efficiency
5× Efficiency Gain Through Superior First-Attempt Accuracy
First-Attempt vs Final Performance
- TDP first-attempt: 82.2%
- Normal 5-attempt: 83.4%
- 5× computational efficiency
Remediation Attenuation:
- First-attempt: +6.09% (d=1.08)
- Post-remediation: +3.22% (d=0.38)
- Advantage drops ~50%
Multi-Attempt Cost Analysis
Per-attempt overhead:
- Token overhead: +25% (315→422)
- Runtime overhead: +38% (0.84s→1.36s)
To match TDP accuracy:
- Normal needs 2.48-2.51 attempts
- Total tokens: +45% vs TDP
- Total runtime: +32% vs TDP
TDP reduces remediation
tasks:
HumanEval:
9.5 vs 13
MBPP: 18.29 vs 44.43
RQ3: Specification-Driven vs Algorithm-Driven Framework
Two Orthogonal Dimensions of Problem Difficulty
Specification-Driven (EASY)
- Algorithmically straightforward
- Precise formatting requirements
- Implicit constraints
- Edge case handling
Example: Task 53.0 - All models failed due to missing trailing newline (100% identical failure)
TDP makes implicit requirements explicit
Algorithm-Driven (HARD)
- Computational sophistication
- Dynamic programming/graph algorithms
- Pattern recognition
- Problem decomposition
Example: Task 271 - Pattern recognition in number sequences (TDP helps marginally)
TDP clarifies constraints but can't convey algorithmic insights
Predictive guidance: Specification-heavy domains (data formatting, API integration) → maximum TDP benefit. Algorithm-heavy domains (optimization, graph theory) → moderate benefit
RQ5: TDP Effectiveness in Mobile Development
8,704 Evaluations Across Android and iOS
Overall TDP Effectiveness
- First-attempt: +2.22 pp
- 95% CI: [1.22, 3.23]
- P-value: < 0.001
- Cohen's d: 0.3974 (small-medium)
- Remediation: +1.98 pp
- 95% CI: [0.91, 3.05]
- P-value: 0.0012
- Cohen's d: 0.2911 (small)
Success Rates
- First-attempt: 12/16 improved (75%)
- Remediation: 11/16 improved (69%)
Performance vs Python:
- Python: 86.90%-91.30%
- Mobile: 66.85%-88.87%
- Gap suggests less mobile-specific training data
RQ5: iOS Consistently Outperforms Android
4-7 Percentage Point Advantage Across All Models
Android (Java) - TDP Results
| Model | Ac@1 | R.Ac |
|---|---|---|
| GPT-4o | 75.81% | 80.36% |
| GPT-4o-mini | 70.74% | 74.64% |
| Qwen-32B | 75.16% | 78.56% |
| Qwen-14B | 73.23% | 73.49% |
iOS (Swift) - TDP Results
| Model | Ac@1 | R.Ac |
|---|---|---|
| GPT-4o | 81.04% | 88.87% |
| GPT-4o-mini | 75.47% | 80.72% |
| Qwen-32B | 78.25% | 85.97% |
| Qwen-14B | 74.34% | 78.07% |
Key findings:
- GPT-4o achieves best performance on both platforms
- GPT-4o-mini shows largest TDP improvement (Android: +3.89 pp, iOS: +3.66 pp)
- iOS advantage consistent across all models → Swift better represented in training data
RQ5: Framework Application Scenarios
Industry-Relevant Use Cases (Part 1)
Scenario 1: Startup MVP
Context: Android prototype, limited budget, multi-attempt OK
Decision Path:
- First-attempt? No → 2b
- Budget? Low → 3d
- Self-host? No
Android: 74.64%
Cost: $0.75/M tokens
Scenario 2: Enterprise Production
Context: iOS production app, maximum quality priority
Decision Path:
- First-attempt? No → 2b
- Budget? High → 3c
- Self-host? No
iOS: 88.87% (best!)
Cost: $12.5/M tokens
RQ5: Framework Application Scenarios
Industry-Relevant Use Cases (Part 2)
Scenario 3: Healthcare Compliance
Context: Android app, privacy regulations (HIPAA), moderate budget
Decision Path:
- First-attempt? No → 2b
- Budget? High → 3c
- Self-host? Yes (required for compliance)
Model Generalizability
Extend recommendations to untested models:
- Claude Sonnet → GPT-4o tier (premium)
- Claude Haiku → GPT-4o-mini tier (budget)
- DeepSeek-33B → Qwen-32B tier (large OS)
- CodeLlama-13B → Qwen-14B tier (medium OS)
Framework applies beyond tested models based on capability tier matching
Research Contributions
Summary of Key Findings
RQ Findings Summary
- RQ1: +4.63 pp (p<0.001, d=0.87), 75% success rate; MBPP +8.40 pp vs HumanEval +0.85 pp
- Results: RQ2 - +6.09% (p<0.001, d=1.08), 16/16 success; democratization 8/10 (80%)
- RQ3: Inverse difficulty: +55.22 pp EASY → +12.96 pp HARD; ρ=-0.97
- RQ4: Ratios 0.25-1.0: +2.90 pp to +6.85 pp, all large effect sizes (d=1.23-2.83)
- RQ5: Mobile 66.85%-88.87% vs Python 86.90%-91.30%; decision framework (3 dimensions: workflow, budget, hosting)
Theoretical Contributions
- First cross-language evaluation (8 languages vs single-language bias)
- Model-agnostic effectiveness (closed/open, 3B-32B+)
- Specification vs Algorithm framework (inverse difficulty mechanism)
- Fully paired evaluation methodology (eliminates selection bias)
- Evidence-based LLM selection framework for mobile development (systematic decision tree mapping workflow, budget, hosting to optimal LLM; 2×2 factorial design generalizable across model generations)
Contributions & Conclusion: Practical Implications
Deployment Guidelines for Practitioners
Model Selection
- Small/medium+TDP over large baseline (80% success)
- Open-source+TDP for high-volume (59× cost advantage)
Test Suite Design
- Specification-clarifying tests (edge cases, formats)
- Start minimal (1-2 tests provide significant value)
Problem Assessment
- Calibrate expectations by specification vs algorithm
- Spec-heavy: +55.22 pp | Algorithm-heavy: +12.96 pp
Evaluation Strategy
- First-attempt as primary metric (5× efficiency)
- iOS +4-7 pp over Android for mobile
Contributions & Conclusion: Conclusion
Test-Driven Prompting: A Rigorous Foundation for LLM Code Generation
Deployment-Ready with Boundary Conditions
- Effect sizes: d = 0.30 - 2.83
- Success rates: 75-100% positive results
- Minimal regression risk: <3.5 pp
Comprehensive Scope
- 8 languages, 8 models
- 3 difficulty levels, 4 test ratios
- 2 mobile platforms
Integration of LLM capabilities with established SE practices like TDD
Bridging academic research and practitioner needs